
新版Google Translate首先瞄准的是中译英(Chinese to English),未来将陆续应用于其他语种的互译。忍不住要赞美一下谷歌:真是敢为天下先,勇气可嘉!澳洲代写先说结论:中译英式写留学生作业基本上不可能,也许能找出别的语种翻译。当然,谷歌并非天真地认为中译英简单,恰恰相反。谷歌项目团队在公告中说,中译英是“出了名的难”。

对此,网友们都炸了,特别是学翻译的小伙伴们:
-作为一个翻译,看到这个新闻的此时此刻,我理解了18世纪纺织工人看到蒸汽机时的忧虑与恐惧……
-换言之···做翻译的人现在开始要被第三次工业革命淘汰了?
-外语系大学还没毕业的开始害怕
-毕业论文英文版有救了!
–一般翻译人员和广大的英专毕业生将获得失业和工资的降低。真正有能力的大神一定有饭吃。但翻译市场只有这么大的需求,除了机器翻译所能替代的部分外,还有多少人能够得到一杯羹?由于机器翻译能力的提高,对翻译的要求越来越低,当真正有实力的翻译人才能够体现自己的价值时,翻译的价值就会随之下降,那时,翻译的价值就不会被衡量。认为英专还是更早找出别的兴趣方向,让英语变得自己比较实际。还希望喜欢这一行的同学继续坚持,成为大神。
那么,新版谷歌翻译底气何在?与旧版究竟有何不同?
我们首先看看旧版谷歌翻译的工作原理。旧版谷歌翻译的核心算法是“基于短语的机器翻译”(PBMT-Phrase-Based Machine Translation)。
简单来说,就是先将一个句子分解为更小的单元—-词或短语,然后在数据库(词典)中寻找对应的译法。这种算法的缺陷是,对分解后单元的翻译是独立进行的,无法顾及语篇,也就是我们常说的“没有语篇意识”。
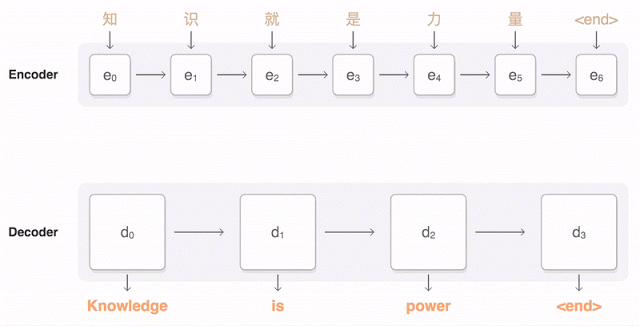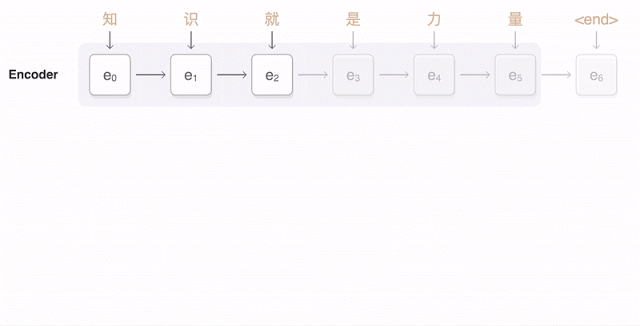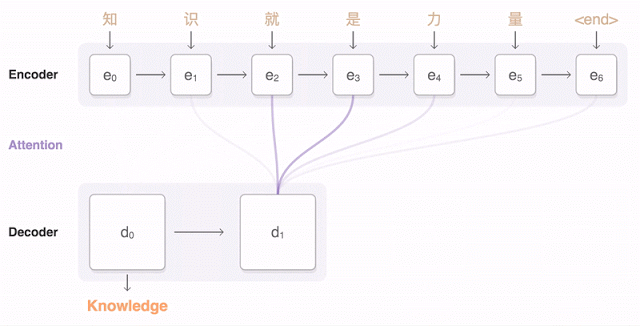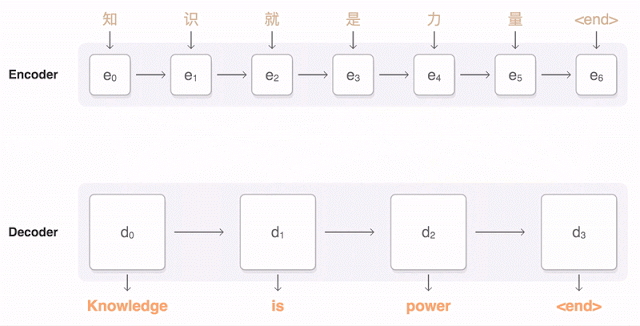
新版谷歌翻译采用的算法是“谷歌神经机器翻译”(GNMT:Google Neural Machine Translation)。与PBMT不同的是,新算法将句子视为一个整体,经过编码、再解码的过程,完成一个句子的翻译。
首先,将一个句子编码成一个【向量】列表,每个【向量】指向一个字的含义,读取整个句子后,再进行解码。为了确保翻译准确,解码时会考虑每个编码向量的权重,找到最相关的中文含义,然后确定译法。
比如,这句“知 识 就 是 力 量”
谷歌项目团队介绍,新的算法大大提高了翻译准确度,相比旧版而言,错误率下降55%-85%。
谷歌还举了几个中翻英的例子:

 英文从左至右,依次是旧版、新版和人工翻译的结果
英文从左至右,依次是旧版、新版和人工翻译的结果
从谷歌给出的例子来看,新版确实比旧版准确多了,稍加修改即可与人工翻译媲美。
忍不住要亲手试验一下,随手输了一句中文。可结果差点亮瞎眼睛!
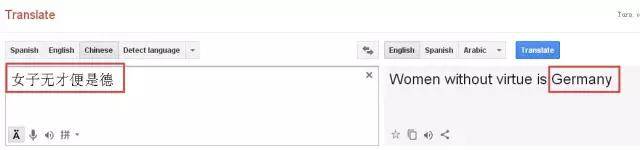
“女子无才便是德” 翻译成“Women without virtue is Germany”。
各位慢慢品吧~~

再来一句有文化的。虽然已经预感到机器翻译不可能把这句词翻译地怎么样,但没想到翻译得这么不知所云。
其实,同样的句子,百度翻译表现更差!对比一下,真的还不如谷歌翻译。
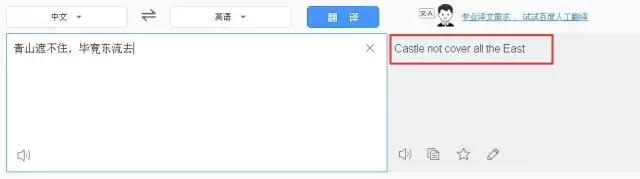
这两个例子提醒我们三点:
一、中译英真的很难!用来写essay基本上不可能!
二、中文博大精深,有时候人脑翻译尚须仔细揣摩中文的意思,何况机器?不可夸大机器翻译的作用,有时候它只会添乱。
经常听到这样的感伤,向外推中国经典文学,最难的是翻译!译本经典,需要以大匠精神,认真对待每个字、每个句子。那肯定是一项费时费力的工作。想象一下,谷歌将《道德经》直接塞进翻译中,会出什么鬼?再说了,还有文化上的差异,有些东西如果原汁原味的翻译成英文,爽的就是会英文的中国人,外国读者可能根本就看不懂。正如金墉的武侠小说一样,只有真正了解、真正喜欢的华人世界,虽然也有英文版,但由于文化差异太大,影响实在有限。
三、虽然新版谷歌翻译的确取得了可喜的进步,但是千万不能过度依赖机器翻译,否则一不小心就被坑!
其实,谷歌项目团队对新版谷歌翻译的表现也不敢托大,他们在公告中这样说:
机器翻译尚远不如人意。“谷歌神经机器翻译”仍会犯一些人脑翻译不会犯的严重错误,比如漏译、误译,以及不考虑语篇只片面地翻译句子。
鉴于机器翻译无法识别复杂的人类情感,文学翻译应该是机器翻译无法企及(至少短期内无法企及)的领域。两三个月以前听吴晓波的讲座,也谈到了人工智能对所有行业的影响,但凡是涉及到需要主观情感做出判断的职业,都只有人脑才能胜任。
文学翻译也是如此。
文艺翻译的范围仅限于对文学作品的翻译,如我们理解的小说。公共关系文案、企业宣传、产品广告等一些海外申请个人陈述等需要文字优美、突出目标特征的翻译需求,都是机器翻译无法进行批量化处理的,仍有很大的生存和发展空间。但是这更考验着翻译的基本功,信达雅,能达到多少程度,每一个译者心中都该有一杆秤。